The Lambda Architecture defines a robust framework for ingesting streams of fast data while providing efficient real-time and historical analytics. In Lambda, immutable data flows in one direction: into the system. The architecture’s main goal is to execute OLAP-type processing faster – in essence, reduce columnar analytics from every couple of seconds to 100ms or so, without actually enabling interesting new applications like real time application of user segments/scoring. As Lambda was conceived, it wasn’t designed to transact and make per-event decisions on the Fast Data, nor to be responsive to the events coming in, as they arrive.
What is Lambda?
The Lambda Architecture is a new Big Data architecture designed to ingest, process and query both fresh and historical (batch) data in a single data architecture. In his book “Big Data – Principles and best practices of scalable realtime data systems”, Nathan Marz introduces the Lambda Architecture and states that:
“The Lambda Architecture.. provides a general purpose approach to implementing an arbitrary function on an arbitrary dataset and having the function return its results with low latency.”
Nathan further defines the system as having both a batch (historical) layer, as well as a speed layer:
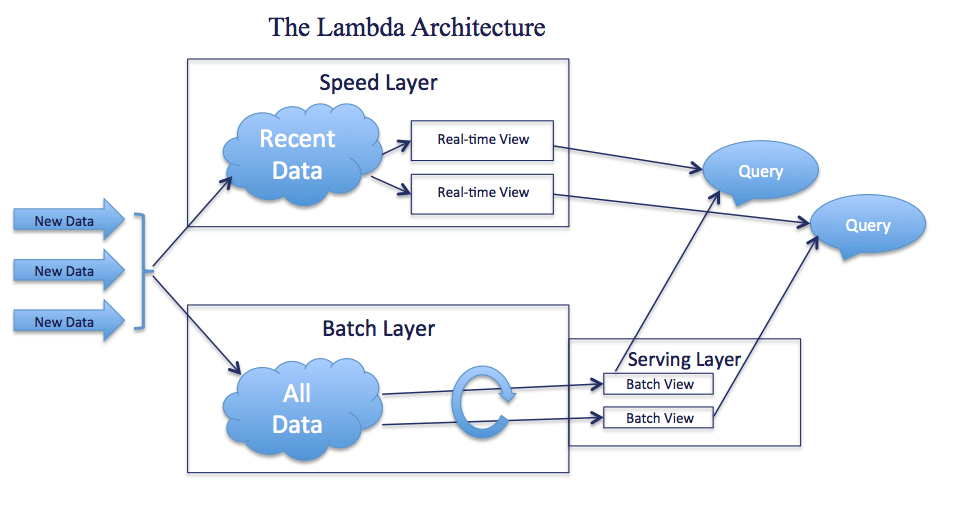
“The Lambda Architecture solves the problem of computing arbitrary functions on arbitrary data in realtime by decomposing the problem into three layers: the batch layer, the serving layer, and the speed layer. “
The batch layer is usually a “data lake” system like Hadoop, though it could also be an OLAP data warehouse such as Vertica or Netezza. This historical archive is used to hold all of the data ever collected. The batch layer supports batch query; batch processing is used to generate analytics, either predefined or ad hoc.
The speed layer is defined as a combination of queuing, streaming and operational data stores. In the Lambda Architecture, the speed layer is similar to the batch layer in that it computes similar analytics – except that it computes those analytics in real-time on only the most recent data. The analytics the batch layer calculates, for example, may be based on data one hour old. It is the speed layer’s responsibility to calculate real-time analytics based on fast moving data – data that is zero to one hour old.
As you can see, if you combine the analytics produced by the batch layer as well as the speed layer, you have a complete view of the analytics across all data, fresh and historical. The third layer of Lambda, the serving layer, is responsible for serving up results, combined from both the speed and batch layer.
To summarize, Lambda defines a Big Data architecture that allows arbitrary queries and computations on both fast-moving data as well as historical data. As noted earlier, the architecture’s main goal is to execute OLAP-type processing faster – without enabling interesting new applications like real time application of user segments/scoring.
“Typical” Lambda Applications
The Lambda Architecture is an emerging paradigm in Big Data computing. New Lambda-based applications are emerging seemingly weekly. However, one of the more common use cases of Lambda-based applications is log ingestion and accompanying analytics. “Logs” in this context could be general log collection, website clickstream logging, VPN access logs, or the popular Twitter tweet stream collection.
Log messages often are created at a high velocity. They are immutable and usually are time-tagged or time ordered. This is the “fast data” that is captured and harvested – it is this data that is ingested by both Lambda’s speed layer and batch layer, usually in parallel, by way of message queues and streaming systems (e.g., Kafka and Storm). The ingestion of each log message does not require a response to the entity that delivered the data – it is a one-way data pipeline.
A log message’s final resting place is the data lake, where batch metrics are [re]computed. The fast layer computes similar results for the most recent “window”, staying ahead of the Hadoop/batch layer.
Analytics at the speed and batch layer can be predefined or ad hoc. Should new analytics be desired, Lambda suggests re-running the entire data set, from the data lake or from the original log files, to recompute the new metrics. For example, analytics for website click logs could be counting page hits and page popularity. For tweet streams they could be computing trending topics.
Volt Active Data and the Lambda Architecture
Volt Active Data is a clustered, in-memory, scale-out relational database. It supports fast ingest of data, real-time ad hoc analytics and rapid export of data to downstream systems like Hadoop and OLAP offerings. It fits squarely and solidly into the Lambda Architecture’s speed layer. Like popular streaming systems, Volt Active Data is horizontally scalable, highly available, and fault tolerant — all while sustaining transactional ingestion speeds of hundreds of thousands to millions of events per second. In the standard Lambda Architecture, the inclusion of Volt Active Data greatly simplifies the speed layer by replacing both the streaming and the operational data store portions of the speed layer.
In the outlined Lambda Architecture, a queuing system like Kafka would feed both Volt Active Data and Hadoop, or Volt Active Data directly, which would then in turn immediately export the event to the data lake.
Future-proofing Lambda
As defined today, the Lambda Architecture is very focused on fast data collection and read-only queries on both fast and historical data. In Lambda, data is immutable – it never changes. Data comes into the system in streams and metrics, both historical and real time, and is calculated and maintained. External systems make use of the Lambda-based environment to query the computed analytics. These analytics are then used to alert, should metric thresholds be crossed, or harvested, for example in the case of Twitter trending topics.
When considering improvements to the Lambda Architecture, what if you could react, per event, to the incoming data stream? In essence, you’d have the ability to act on the incoming feed, in addition to performing real-time analytics.
Here at Volt Active Data we have a lot of experience building streaming applications for fast data, another term for the Lambda-defined “speed layer”. Most of our customers are building fast data applications, providing us with unique insight into the Lambda speed layer. These systems ingest events from log files, the Internet of Things (IoT), user clickstreams, online game play, and financial applications. While some of these applications passively ingest events and provide real-time analytics and alerting on the data streams (in typical Lambda style), many of these applications have begun interacting with the stream, adding per-event decisioning and transactions in addition to real-time analytics.
Additionally, another characteristic of these systems is that the speed layer analytics can differ from the batch layer analytics. Often the data lake is used to mine intelligence via exploratory queries. This intelligence, when identified, is then fed to the speed layer as input to the per-event decisions. Scott Jarr describes this fully interactive Lambda-like application evolution here, https://voltactivedata.com/blog/youd-better-do-fast-data-right/ in his Fast Data blog.
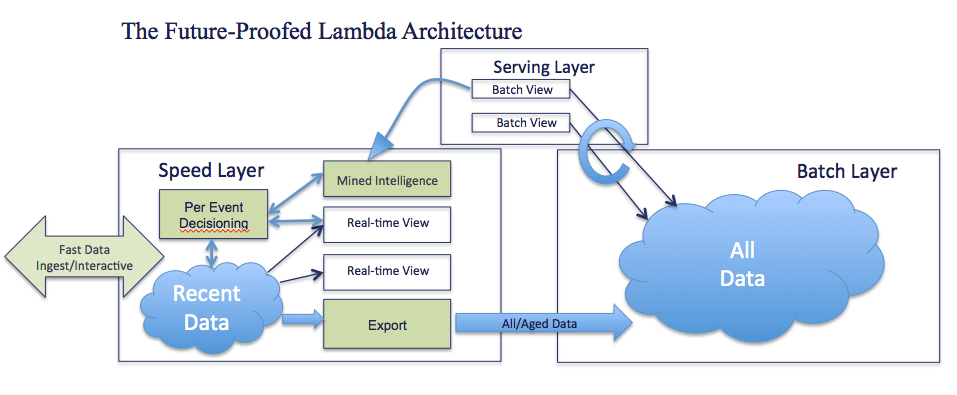
In this diagram you can see the additions to the architecture:
- Data arrives at a high rate and is ingested. It is immediately exported to the Batch Layer, the Data Lake.
- Historical intelligence can be mined from the Data Lake and the aggregate “intelligence” can be delivered to the Speed Layer for per-event real-time decisioning (for instance, to determine which ad to display for a segmented/categorized web browser/user).
- Fast data is either passively ingested, or a response can be computed by the new decisioning layer, using both real-time data as well as historical “mined” intelligence.
For a working code example of the simplified speed layer, reference the Volt Active Data “fast data” application posted here: http://voltdb.github.io/app-fastdata.
Conclusion
The Lambda Architecture is a powerful Big Data analytics framework that serves queries from both fast and historical data. However, the architecture emerged from a need to execute OLAP-type processing faster, without considering a new class of applications that require per-event decisioning: applications like real time application of user segments/scoring, fraud detection, denial of service attacks, policy and billing, etc. In its current form, Lambda is limited: immutable data flows in one direction, into the system, for analytics harvesting.
Adding Volt Active Data, a linearly scalable in-memory relational database, into the Lambda Architecture greatly simplifies the speed layer by reducing the number of components needed.
Lambda’s shortcoming is the inability to build responsive, event-oriented applications.
In addition to simplifying the architecture, Volt Active Data provides future-proof functionality to Lambda, specifically, the ability to execute transactions and per-event decisions on fast data as it arrives. Rather than a one-way streaming system feeding events into the speed layer, adding an ingestion engine like Volt Active Data provides developers with the ability to place applications in front of the event stream to capture value the moment the event arrives, rather than capturing value at some point after the event arrived on an aggregate-basis.
Volt Active Data improves the Lambda architecture by:
- Reducing the number of moving pieces, the products and components, needed.Specifically, major components of the speed layer can be replaced by a single component, Volt Active Data. Further, Volt Active Data can be used as a data store for the serving layer.
- Enables the ability for the application to make per-event decisioning and transactional behavior, without re-implementing the architecture once deployed.
- Providing the traditional relational database interaction model, with ad hoc SQL capabilities, on fast data. Applications can use standard SQL, providing agility to their query needs without requiring complex programming logic.
- Providing access to standard analytics tooling, such as Tableau, MicroStrategy, and Actuate BIRT, on top of fast data.




