The development team at Volt Active Data recently ran Volt Active Data v4.2 against the Yahoo Cloud Serving Benchmark (YCSB), an industry-standard performance benchmark for cloud databases. We ran our test on as realistic a cluster setup as possible: commodity hardware that we could easily book as spot instances on EC2, with features like durability and high availability enabled. And we ran a varied mix of workloads with realistically sized, 1 KB rows, rather than focusing on a specific, overly favorable use case. And since YCSB is, after all, a benchmark for cloud systems, we ran the test in Amazon’s public cloud to show that Volt Active Data can maintain consistently exceptional performance even when faced with the inherent variability of such an environment.
We’re pleased to report we achieved best-in-class performance numbers against this challenging test.
A little about YCSB
YCSB is a popular open source benchmark designed by Yahoo Labs. Their project starts from the observation that the new generation of database systems – NewSQL, “key-value”, and the rest – address workloads that often differ significantly from those measured by more traditional benchmarks such as TPC-C. Not just that, but users of these systems do a wonderfully diverse range of things with them, making it unlikely that a single conventional, domain-specific benchmark could be up to the task of providing head-to-head comparisons that would be meaningful to any large portion of potential users.
YCSB addresses this problem with the idea that simple building blocks and a set of tunable parameters can create a benchmark that is both easy enough to set up and run against a wide variety of systems, and flexible enough to be useful to a wide range of audiences. It operates on a loose schema consisting of a string key mapped to a collection of fields, which themselves are string to binary blob key-value pairs. Workloads are implemented as combinations of elementary operations such as inserting or reading a record for a single key. The YCSB benchmark also implements a more challenging “scan” operation, which in this context refers to a paging operation starting from a given key.
The generality that YCSB offers has resonated with many people. On-demand direct comparisons are very frequently desirable during the early stages of selecting a database, when people can feel overwhelmed by the large number of choices on the market. And tuning YCSB to meet the approximate workload of a given application is as easy as adjusting in a single properties file a few variables such as the number and size of fields and the percentage composition of operations.
Must Read: 5g Enterprise Use Cases
Running YCSB Against Volt Active Data – our test
Our test targeted three core YCSB workloads: Workload A (50% read/50% update), Workload B (95% read/5% update), and Workload E (95% of the paging “scan” operation of up to 100 rows/5% insert). This combination gives a representative view of the kinds of things YCSB is used to test. The trials ran on paravirtual (PV) c3.8xlarge instances running Ubuntu 13.10. These instances are based on Intel Xeon E5-2680 v2 (Ivy Bridge) processors (meaning 32 logical processors) with 60GB each of memory, and have 2 x 320GB SSD for storage. The clusters ran in the us-east-1e availability zone and were configured in a single placement group, meaning all involved machines should have been networked together by low-latency, full bisection 10GbE. Additionally, all instances were reserved via spot request. Volt Active Data was configured with 24 sites per host, k-factor of 1, and asynchronous command logging.
First, I tested scenarios against 3, 6, 9, and 12 node setups, where each cluster was matched with 150 client threads per server node, distributed such that no client machine was managing more than 300 threads. Further, I implemented the YCSB client to assign one instance of the Volt Active Data Java client to each 50 YCSB threads. The purpose in this trial was to ensure that the database was running at load in order to measure peak throughput.
Second, I ran against a 12-node cluster and incrementally added client threads. This was accomplished by adding additional client machines, each running 150 threads. The purpose here is to demonstrate how much load the cluster can handle before seeing a noticeable impact in terms of latency. It’s worth noting in these results that latencies remain essentially flat until a point just short of peak throughput. This behavior is not only true of average latencies, but is completely preserved at the 99th percentile.
In all cases, the database was preloaded with 10 million records per node using the YCSB defaults of 10 fields with 100 bytes each, and the workloads ran on each setup for two independent 10 minute trials.
The source for our YCSB client implementation is public, and may be found at http://github.com/Volt Active Data/voltdb/tree/master/tests/test_apps/ycsb. As described in the attached readme file for that code, in order to reproduce the trial you will need to obtain the YCSB benchmark separately. YCSB is itself an open source project, and may be obtained at https://github.com/brianfrankcooper/YCSB. As of the running of this test, the current version of YCSB is 0.1.4. Since we do not maintain YCSB, we can’t guarantee that future revisions will not break compatibility with our driver.
Results
Workload A
First up are the results for workload A, which is a 50-50 mix of read and update operations. In terms of throughput, we saw an increase from 182k transactions per second for 3 nodes to 449k for 12 nodes.
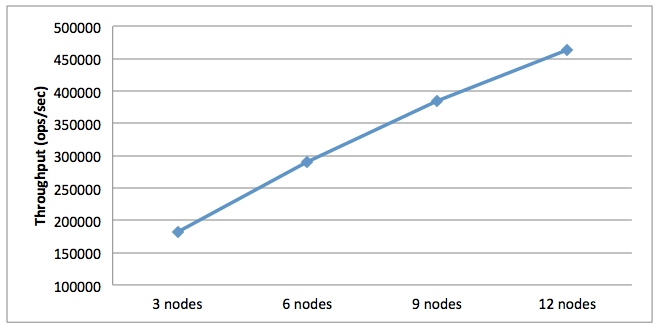
Figure 1. Workload A Average Throughput
Moving to latencies, we see that the 12-node cluster was able to sustain a high degree of responsiveness through 360k transactions per second.
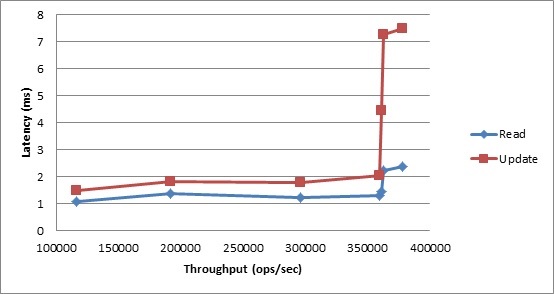
Figure 2. Workload A Average Latency vs. Throughput
Workload B
This workload mixes 95% reads with 5% updates. We see strong throughput results for this workload, scaling from 285k TPS for 3 nodes to 724k TPS for the 12-node cluster.
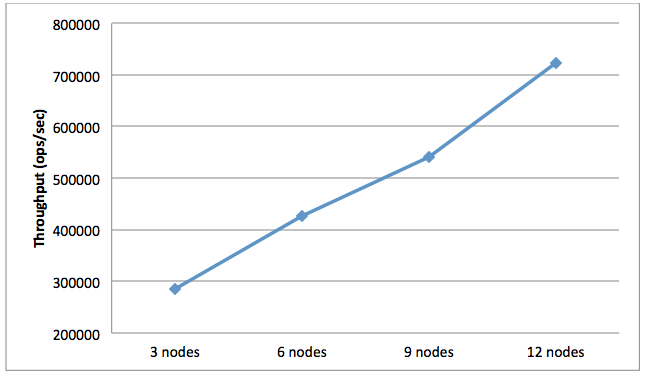
Figure 4. Workload B Average Throughput
In terms of latencies, we see very favorable results as well, with very low latencies holding nearly constant up until quite close to the peak throughput seen above. To get a sense of what this means in terms of the real world, observe that at 692k TPS those latency graphs are still essentially flat. Those 692k transactions were as much work as 1,050 client threads could produce, which is a huge number of concurrent connections.
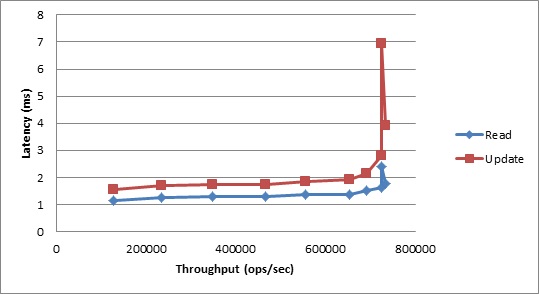
Figure 5. Workload B Average Latency vs. Throughput
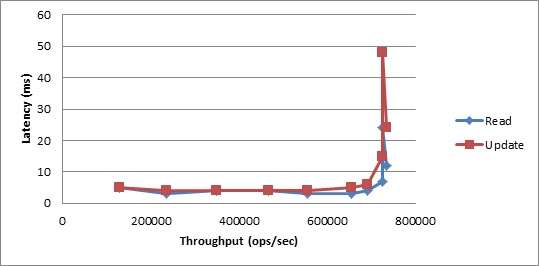
Figure 6. Workload B 99th Percentile Latency vs. Throughput
Workload E
Workload E implements the more complicated paging “scan” operation, which can request up to 100 rows at a time, and could potentially require data from more than one partition in a variation on the “run everywhere” strategy. In fact, a full 95% of operations in this workload are this scan, with inserts filling out the rest. Despite needing to synchronously carry out this much larger operation, which has the definite potential to become network bound, we observe a respectable 163k TPS for the 12-node cluster.
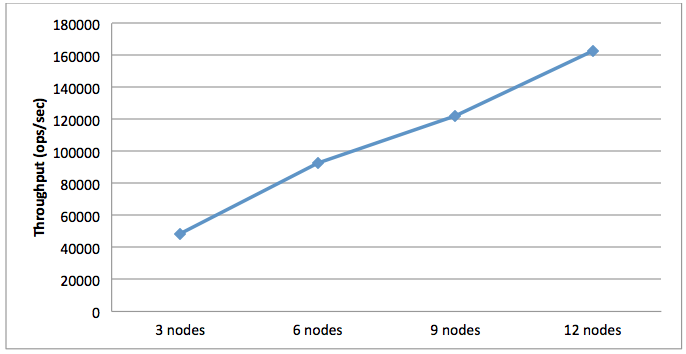
Figure 7. Workload E Average Throughput
In terms of latencies, we expectedly see somewhat higher numbers for this workload; cloud environments are inherently less predictable in terms of performance. This is due to the much larger volume of data being communicated over the network. Again, Volt Active Data performed extremely well; the latencies displayed below are not large, and are quite steady until right up against the peak throughput.
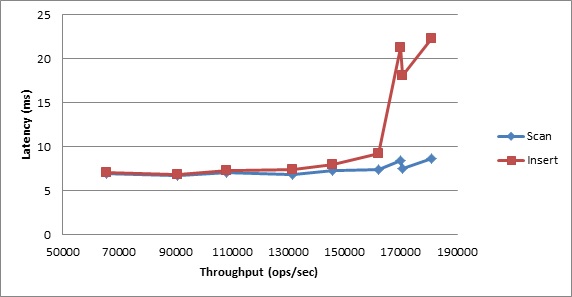
Figure 8. Workload E Average Latency vs. Throughput
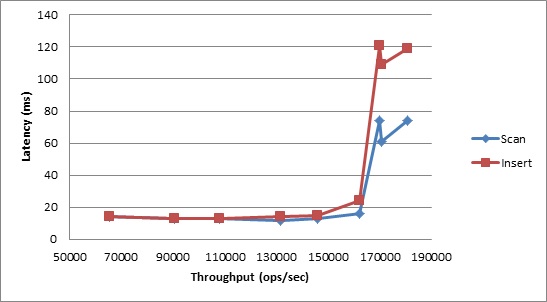
Figure 9. Workload E 99th Percentile Latency vs. Throughput
A little history
In 2012 a group of academic researchers used YCSB to benchmark Volt Active Data v2.1 along with several other systems in a paper entitled “Solving Big Data Challenges for Enterprise Application Performance Management”.[1] The paper suggests that the configuration used was largely out-of-the-box. We would have liked to recreate their exact test on a current version of Volt Active Data, but this was not possible since the researchers didn’t make their client implementation publicly available. It’s worth noting that the version of Volt Active Data tested in the paper is old, and today’s system is a lot faster, as shown in the results documented in this analysis.
Current results surpass expectations
Volt Active Data’s numbers in the YCSB benchmark are stronger than any comparable tests published to date. There are all kinds of configurations and testing scenarios out there – that’s the nature of flexibility – but nothing matches these numbers with real world-sized data running in the cloud against a real world-ready, highly available, durable cluster. For each workload, Volt Active Data displays essentially linear scaling behavior. For Workloads A and B, even as we’re pushing well into the hundreds of thousands of transactions per second, 99th percentile latencies stay fixed at around 4 or 5 milliseconds, while for Workload E, where each operation is handling up to 100 times more data, that number increases to only 13 milliseconds. Against Workload B, which for obvious reasons tends to be the most commonly reported result, we achieve 724,000 average transactions per second (TPS) on the 12-node cluster. That’s big, and it’s how Volt Active Data performs.
Worth noting is that, as good as these numbers are, in Volt Active Data’s world they’re not exceptional. For example, going all the way back to Volt Active Data version 1.1, SGI ran our own “voter” benchmark against their Rackable C1001-TY3 cluster. This benchmark application does a bit more than YCSB does in each of its transactions, and with 10 server nodes they achieved a rate of about 1.2 million transactions per second. With 30 nodes, it scaled linearly all the way to 3.37 million TPS.[2] More recently, running a simple, key-value workload with a 90% read/10% write mix against just a 3-node, k-factor 1 cluster of Dell R510s, we observed a maximum throughput of about 950,000 TPS, with consistently good latencies up to 800,000 TPS. Yes, that’s on only 3 server nodes.[3]
The fact that Volt Active Data in undaunted by YCSB is just one small piece in a larger performance story. These results do a good job of showing this popular benchmark is no problem for Volt Active Data!
[1] Rabl, Tilmann et al. 2012 VLDB Endowment.http://vldb.org/pvldb/vol5/p1724_tilmannrabl_vldb2012.pdf(link is external)
[2] https://www.sgi.com/pdfs/4238.pdf(link is external)
[3] https://voltactivedata.com/blog/voltdb-3-x-performance-characteristics/




