
We recently received a question from a customer who was looking for a quick way to repurpose some Volt Active Data production servers to create a disaster recovery site. The customer had a 5-node cluster with a k-safety factor of 2, which means the cluster maintains three synchronized copies of each record, distributed on different nodes in the cluster, and the cluster can survive the loss of any two nodes. They wanted to reduce the size of this cluster to three nodes and use two nodes to form a replica cluster at another site for disaster recovery.
The customer wanted to know: Can I do this? How? Which configurations are recommended? What actions should I take if a node fails on either cluster, or if either cluster fails?
These are fairly involved questions, but they come up frequently enough that we thought it would be good to share the answers. Here goes.
Say you have five Volt Active Data servers in production, with k-factor=2, and no disaster site. You want to shift some of these servers to create a disaster recovery site.
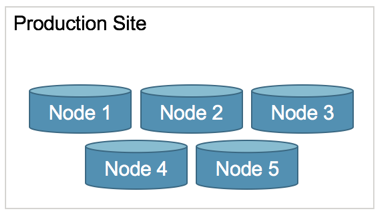
The simplest configuration might be called a “balanced” approach. This has always been a supported configuration of Volt Active Data database replication. The master and replica clusters have identical cluster configurations (hostcount, sitesperhost, k-factor):
Production: 3-nodes, k=1 or k=2
Replica: 3-nodes, k=1 or k=2 (you’ll need one additional node)
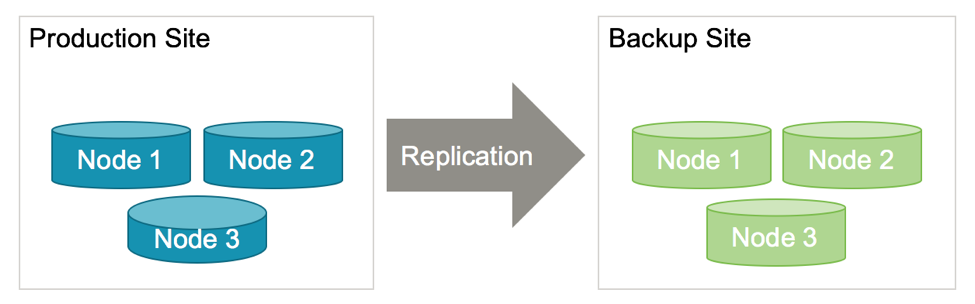
In the v6.2 release, Volt Active Data introduced support for a feature that allows replication between clusters with different sizes and configurations (hostcount, sitesperhost, k-factor).
Here’s how we explain it in our Documentation:
Support for different cluster sizes in passive Database Replication (DR)
Previously, passive Database Replication (DR) required both the master and replica clusters to have the same configuration; that is, the same number of nodes, sites per host, K factor, and so on. You can now use different size clusters for passive DR. You can even use different values for partition row limits on DR tables. However, be aware that using a smaller replica cluster could potentially lead to memory limitation issues. Be sure to configure both clusters with sufficient capacity for the expected volume of data.
This feature allows more flexibility in planning for a disaster recovery site cluster, including using a smaller cluster with reduced redundancy. For example:
Production: 3 or 4 nodes, k=1 or 2
Replica: 1 or 2 nodes, k=0
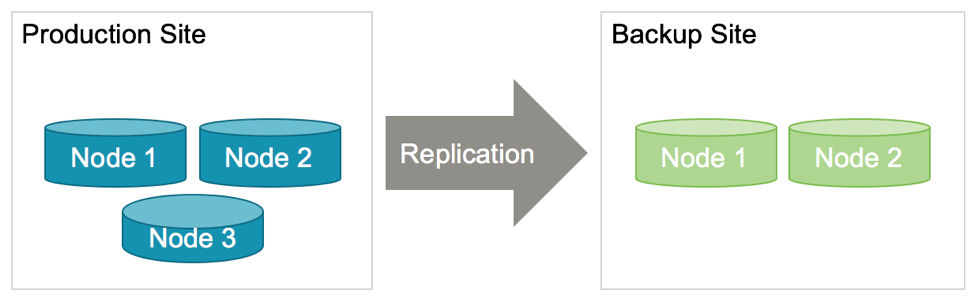
This allows the customer to use the existing five servers in a new configuration that trades off some level of high availability redundancy for disaster recovery and geographic redundancy.
Notice that we don’t recommend k-factor=1 for a two node cluster. We always recommend clusters of three or more servers when using k-safety. A cluster of only two servers with k-factor=1 is essentially two mirrored servers. This configuration has a 50% risk, if one node fails, that the other node will stop as a protection against split brain syndrome. Since this offers only 50% redundancy, it’s usually not worthwhile. A three-node cluster is much more resilient.
The exception to this is when the k-factor=0 (no redundancy). In that case, any node failure will stop the entire cluster, so there is no risk of split brain with two servers. While this may not provide the level of HA necessary for a production application, some customers ask for the mixed cluster size feature (available in v6.2) because they want to use a lower k- factor (even 0) on the replica cluster to lower hardware costs.
Keeping the lights on
If an individual node fails on a cluster with k-safety, the cluster will survive. The node can then be restarted and it will rejoin the cluster, get a fresh copy of data from its peers, and then resume executing transactions in parallel with the other nodes. Since v6.7, the command to restart the node is the same as the command used to start all the nodes in the cluster, so this can be automated quite easily.
If a production (or master) cluster fails because the number of nodes that individually failed exceeds the k-factor, or because the nodes lost connectivity, you have two choices. You can restart the cluster and recover the state from the disk, or you can promote the replica cluster to take over the mastership of the data.
If you restart the cluster, it will recover the state from the latest committed transactions on disk. Recovery time can vary depending on the amount of data, the number of nodes, the hardware, and the number of indexes and views in the schema. Generally, it is measured in minutes. However, the advantage is that no committed transactions were left behind and the replication automatically resumes as soon as the master cluster has completed recovery.
The alternative is to promote the replica cluster using the “voltadmin promote” command. This takes only a fraction of a second to change the role of the cluster to master, so it will begin accepting write commands from clients. This command is made manually, as opposed to having the replica cluster promote itself automatically when it loses connection to the master. This is because connectivity may be lost temporarily and then resume, and customers may prefer to control which action to take in the event of a cluster failure. Some customers use scripts or monitoring tools to automate this.
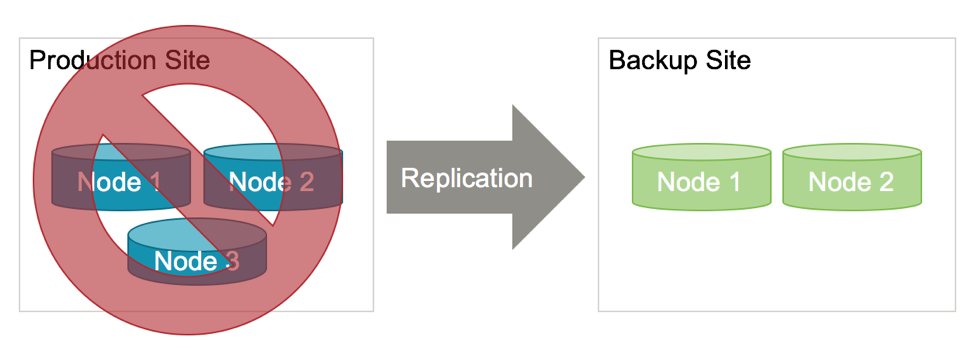
One consideration is availability vs. completeness. Promoting the replica cluster is the fastest way to return the database to availability, but it can involve some data loss because the replica cluster receives changes asynchronously from the master cluster, and will lag behind, typically by some fraction of a second, depending on the geographic distance and network capacity.
Recent requests made to the master cluster could have been at various stages of completion when the cluster failed. Some requests may have been waiting to be executed. Others may have executed in memory, but were not yet written to disk. Others may have been executed and written to disk, so they would be recovered if the master cluster were to be restarted, but their changes might not have been sent to the replica cluster yet, and their responses might or might not have been sent back to the client. It is possible for some of these transactions to have been committed with a commit response sent back to the client, but to have not made it to the replica cluster yet. By promoting the replica, those changes would be left behind (but could be retrieved manually later once the master cluster has restarted).
Once you have promoted the backup cluster, you just need to point the client applications to the backup cluster. Some customers automate this as well, programming their clients to connect to the backup cluster automatically when they lose connection to the master cluster.
Restoring the Production site
If you have promoted and shifted the workload over to the replica cluster, you will want to bring the production site back up and switch back as soon as possible, especially if the replica cluster has no redundancy.
This can be done using the same process, by changing the configuration of the cluster at the production site to be a replica, and restart it so that it begins replicating from the (now master) cluster running at the backup site:
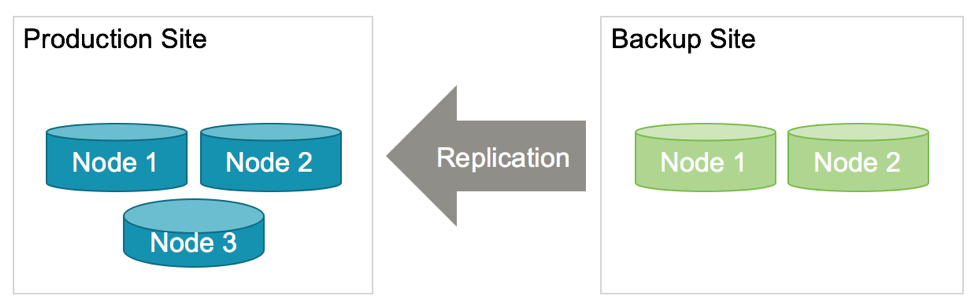
Once your production site is back up, you can make it the master once again, so you have returned the clusters to their original configuration and can enjoy the full redundancy as planned. This time, however, you can avoid any loss of data by using a controlled cutover process.
To do that, first wait until the production site cluster has completed initializing and has completely resumed replicating in the reverse direction. It may take a few minutes to copy over the data from the backup site and resume the flow of replicated changes, but you can monitor the progress online.
Once the replication of changes has resumed, pause the database at the backup site. For a brief period of seconds writes will not be allowed. You can monitor to see that the changes have completely replicated over to the cluster on the production site. Then, stop the backup cluster and promote the primary cluster to be the master once again. Lastly, restart the cluster at the backup site as a replica so everything is back in the original configuration. This is a ‘controlled failover’,0 as described in the documentation, “Stopping Replication“.
A good reference for situations like that described above can be found in the Admin Guide on using DR to perform a Volt Active Data software upgrade. This chapter takes readers through the steps for a controlled failover, reversing the direction of replication, and a controlled failover again.
Stay tuned for more support Q&As – and don’t forget to download our newest version, v7.2.




