I recently gave a talk at the Strata + Hadoop World conference in San Jose on the benefits of integration of processing and state and transactions when solving stream processing problems. The talk described how a system like Volt Active Data makes the following things easier:
-
- Correlation and streaming joins
- Out-of-order message delivery
- Exactly-once processing semantics
- Precision accounting
- Complex, non-commutative statistics
- Event-time vs. processing-time statistics
I could have made a high-level argument about how the integration of processing and state makes these problems much simpler, or how making event processing transactional simplifies so many things and makes user code more robust. But these are the kinds of improvements that need to be shown, not described. To really be convincing, the argument has to be backed by a concrete example and honest to goodness code.

I’ve worked on customer applications that solve all of these problems, sometimes all in the same application, using Volt Active Data. While the examples in our download kit cover many patterns, features and use-cases, there wasn’t an example that really covered the transactional stream processing use case. I set about simplifying a customer use case into an example that would back up the presentation and could be included in our download kit.
The Problem
We’re going to build software to manage call centers. Our customers each have thousands of agents standing by, and millions of callers. Callers call into agents, and these calls generate events. Common events are things like the start of a call, placement into a queue, transfer from queue to agent, end call, etc. We need a system to ingest these events and record a perfect picture of what was happening in the call center. This data supports billing data for our customers, as well as monitoring and dashboard data so they can understand their call center businesses.
Volt Active Data is a good system for building this kind of app. The problem plays to many of Volt Active Data’s strengths. It has to correlate events relating to the same call in order to track a call as it happens, updating state in real-time. It has to manage delayed, duplicated or swapped events. And it has to perform accounting and statistics in real-time to support the business.
To make this problem into a good example, we simplify a bit. The example I built for the Strata presentation focuses on two call events, begin and end. All of the same problems are still present, but the complexity is much lower.
Naive Correlation
Let’s imagine a first pass at this application. First we’ll create two tables, one for calls in progress and one for completed calls. Since Volt Active Data is 100% ACID transactional, it’s easy and safe to move matched events into the completed table and remove them from the first.
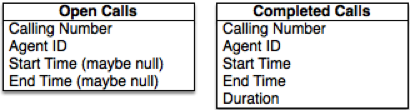
We can sketch out our event handling logic like so:
BEGIN CALL:
Add a record to Open Calls
END CALL:
Lookup matching record in Open Calls to get call start time
Delete matching record in Open Calls
Insert completed call record into Completed Calls
Handling Out-of-order Events
The logic above works in the common case, but assumes too much. Real world event delivery is often messier. We’ll start by handling out-of-order delivery. What if an END CALL event is received before a BEGIN CALL event? The answer is to make the event processing code much more symmetrical.
BEGIN CALL:
Check for matching record in Open Calls…
If there’s a match:
Delete matching record in Open Calls
Insert completed call record into Completed Calls
If there’s no match:
Insert new call record into Open Calls.
END CALL:
Check for matching record in Open Calls…
If there’s a match:
Delete matching record in Open Calls
Insert completed call record into Completed Calls
If there’s no match:
Insert new call record into Open Calls.
Even though this code is identical, some of the implementation details will be slightly different. For example, checking for a match to an END CALL event is ever so slightly different than a BEGIN CALL match, because they check for different NULL fields.
Filtering Duplicate Events
The above code handles out-of-order events, but what about duplicate events? This is a pretty common occurrence, and I’ll explain why.
When an upstream event source sends one or more events to the system, but doesn’t receive a confirmation due to network problems, software failure or hardware failure, it has a choice. The upstream software can resend the events, or not. If it resends them, there is a risk of repeat delivery. If it doesn’t resend, there’s a chance the target system didn’t successfully process them. We refer to this as choosing between at-least-once and at-most-once delivery. Note that you can certainly have a system that is neither at-least-once nor at-most-once; I’ve seen them in production. You can’t, on the other hand, have a system that delivers messages exactly once in all situations in the face of real-world computing and networks. (See http://bravenewgeek.com/you-cannot-have-exactly-once-delivery/).
So the best approach is to build an at-least-once delivery system and use strong consistency in the processing engine to deduplicate events.
The way Volt Active Data deduplicates is by making its processing logic idempotent. Idempotence (https://en.wikipedia.org/wiki/Idempotence) is the property of some operation that applies if the operation has the same effect if it is applied once, or several times. For example, “set x to 5” is idempotent; you can do it several times and x will still be 5. “Increment x” is not idempotent; one increment is very different than several increments.
So let’s make our previous logic for END CALL idempotent. We’ll skip BEGIN CALL, as it’s very similar to END CALL.
END CALL:
Check for matching record in Completed Calls…
If there’s a match (we’ve seen this event before):
Stop processing.
Check for matching record in Open Calls…
If there’s a match but it’s missing a start time (we’ve seen this event before):
Stop processing.
If there’s a match missing end time:
Delete matching record in Open Calls.
Insert completed call record into Completed Calls.
If there’s no match:
Insert new call record into Open Calls.
We’ve added two extra checks and traps, both leading to a “Stop processing” command. These two situations mean this is not the first time the system has processed this event, and thus we don’t have to do any work.

Good news, everyone! We’ve now built correlation code that processes out-of-order and duplicate events, yet it’s still very straightforward. The fact that, in Volt Active Data, the entire processing logic for an event is a transaction means we don’t worry about the system failing in the middle of our logic. We also don’t worry about other events interfering with our checks. If you check a value at the start of your logic, it won’t change under you unless you change it. This means less error handling on the server-side, and often less error handling on the client side. If a client is unsure if work was done, resend it until it’s sure (though exponential backoff is smart too).
Calculating the Mean Call Time By Agent (Event-Time vs Processing-Time)
The application wants to calculate mean call duration by agent, and then possibly slice it up by time period. Let’s slice it by the hour for this example. There are a couple of things to consider.
First, if a call starts at 2:59pm and ends at 3:01pm, do we bucket it in the 2pm-3pm hour or the 3pm-4pm hour? The choice seems to be bucketing by start time or end time, but there could be more sophisticated options. We could even keep multiple stats. The good news is that for the purposes of the example, it doesn’t matter. This is one of those questions you have to really solve when building a business, but since whatever is decided doesn’t change how an example works, we can punt, happily, and just pick one. Let’s just go with the call end time.
More good news: calculating a mean is pretty simple. We can record the number of calls ending each hour, and we can sum the total duration. This is done as we process each matched BEGIN CALL and END CALL event, so the sum and count stored are always current and up to date. This means that when we need a mean calculation for a given hour, we don’t have to scan lots of rows; in fact, we scan just one. We get the mean using something roughly like:
SELECT SUM_DURATION / FREQUENCY AS MEAN_DURATION WHEN HOUR = ?;
Still more good news: we’ve solved our second major issue without really thinking about it, just by using a relational database in a sensible way. The second problem is whether to divide the sums and counts by hour of message arrival, or by the hour that corresponds to the timestamp on the message.
Many systems, when asked to aggregate by hour, collect the set of messages that arrive during a particular hour and bin them up together. As soon as the clock rolls over, they begin a new aggregate value. This is simpler in that only one value is updated at a time. Once the hour ends, the data for the previous hour is essentially immutable. The problem, of course, is that it might also be wrong.
Networks inherently have delay, though many argue that a 5ms network delay isn’t going to fundamentally change the dashboard. The issue is that 5ms is typical, but far from the worst case. Many times when networks, software, or hardware go down, messages stop sending, but are buffered at the source. When things sort themselves out, all of the messages are delivered, possibly seconds, minutes or even hours late.
Volt Active Data, and most databases with strong consistency, makes updating old values trivial. The biggest difference with Volt Active Data is Volt Active Data can do it fast enough for intensive stream processing problems. So yes, the dashboard may be off if messages are delayed, but as they arrive it will be updated to reflect the most correct answer possible.
Calculating the Standard Deviation By Agent
Let’s try something less straightforward – calculating a running standard deviation of call duration per agent for a given day. Note that I fully understand the standard deviation is a pretty lousy metric for this use case, but it’s mathy, and that’s what we want for this example. The point is to demonstrate that if you can calculate something incrementally, even if complex and noncommutative, you can probably calculate it on a stream. This assumes you have a transactionally consistent stream processor.
Here’s the formula for calculating the standard deviation for a population:
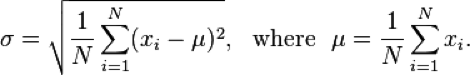
This formula isn’t going to work, because each incremental value in the outer summation relies on an inner summation (the population mean) that changes with every new value. So we can’t calculate this incrementally.
The good news is there is an incremental way to calculate standard deviation. Read about it on the Wikipedia page here: https://en.wikipedia.org/wiki/Standard_deviation#Rapid_calculation_methods
The formula calculates a Qk in terms of Qk-1 and the existing mean using the formula:
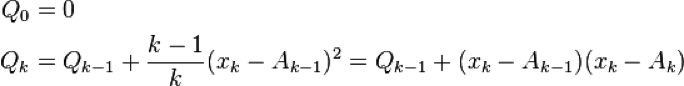 And from Qk you can calculate the variance (the square of the standard deviation) using:
And from Qk you can calculate the variance (the square of the standard deviation) using:
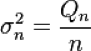
This gives the standard deviation using a simple square root.
To add this to our Volt Active Data example and keep track of standard deviation of call duration by agent by day, we add a third table.

Now when a new sample arrives, we use the date and agent to find the appropriate row (creating it if necessary). We calculate a new Qk based on the current Qk, the current sum and the new data. Finally, we calculate the current standard deviation and store it in the table.
We can write this code in a very straightforward way. We do still have to worry about whether a calculation can be performed incrementally. We need to worry about rounding errors with floating point numbers. And we also have to worry about horizontal scale, but much of the work goes away when the stream processing system is transactionally integrated with state.
But again, we don’t have to worry about failing in the middle of this calculation. We don’t have to worry about values changing out from under us when we calculate this value. In fact, we can just put this code in a separate method, and call it from our BEGIN CALL and END CALL processing code, without worrying about breaking or corrupting anything.

Conclusion
At Volt Active Data we are working hard over the course of 2016 to expand the number and breadth of examples shipped with the download kit. Having a representative set that shows the kinds of problems users are solving with Volt Active Data, while offering a concrete implementation, can jumpstart a number of users’ developments. One of our first examples, Voter, has not only been used to power actual television talent contests, but also has inspired benchmarks from other vendors, including Amazon Web Services.
The Call Center example is a big addition. It’s the first example to really demonstrate precise calculations on streams, involving joins, out-of-order messages, duplicated messages, and non-trivial math. It doesn’t really show throughput (due to the way the data is generated, not because Volt Active Data is bottlenecked), but we have many examples that do that.
Compare the amount of code required for an application like this to applications written on platforms without transactionally integrated processing and state. The comparison is stark. If you’d like to try to build this app on another stack, we encourage you. Let us know how it goes.
And if you have a suggestion for additional examples we could develop, email us at info@voltactivedata.com.




