Choosing a database is a complex affair. Is performance the most important factor in the decision? Is the selection constrained by incumbent infrastructure and applications? Or are you working on a new application and feel free to consider the newest, hottest technologies – but then you need to decide which to use?
Wading through available technologies and assessing not only listed features/benefits but also evaluating competing marketing claims can seem more arduous than building a DIY solution.
Additionally, limiting your selection based on technology already being used or to the newest entrants in the data management world may not be the best approach with which to begin a search. Two considerations really should rise to the top of the selection criteria list:
- What is the application (really, what problem are you trying to solve)?
- Are you using the database to support actions – a request/response workflow – or are you using it to analyze fast streams of data that then will be pushed to a longer-term store?
The differences here are stark, if overly simplified. One use case is transactional and operational in nature – it’s safe to conclude this use case puts the database directly in a company’s revenue path. A model customer could be a mobile provider, an ad tech company, an online gaming company, a sharing-economy application, or a utility company implementing an IoT application.
The second use case is observational, perhaps even anecdotal in nature – data is analyzed, perhaps aggregated, but isn’t used to take an immediate action. In this case the end-user might be a pure reporting application, one where the eventual consistency issues of NoSQL solutions don’t appear to be a big problem – although separating analytics from decisions likely will prove to be a false choice down the line. And you are potentially sacrificing an opportunity for (near) real-time interaction.
Even when the enterprise architect or developer is familiar with all available options, from conventional RDBMSs to NoSQL to in-memory databases, the decision can be difficult. It may appear that focusing on performance exclusively points to NoSQL; it may be that installed infrastructure investments top all other factors; it may be the volume of data, rather than its velocity, is the chief concern.
One consideration, which might not make it to the top of the list, is complexity. Both traditional-tech and new-tech folks can be blindsided by complexity – how else to explain intricate, recursive designs where incoming data feeds are replicated to three or more sources before processing? With this in mind, and after talking to our customers, we decided to look at some before-and-after scenarios in which Volt Active Data was implemented to increase performance, add ACID transactionality, and simplify architectures.
Before – a financial services use case
Envision the infrastructure supporting the broker-trader operation of a large global bank.
The bank, whose traders serve high net worth clients, has high-velocity streams of incoming event data – tick feeds, trade data, orders and fills, and so on – arriving via the cloud from some number of devices. This data was processed by a number of applications (as shown in the “Before” architecture picture below). Each application had its own database in front of the application that had to replicate data simultaneously to a Cassandra cluster, a Hadoop cluster, and a message bus that maintained logic to publish state back and forth, in addition to processing queries from traders and analysts who had to answer questions, like “What is state of this trade?”. MySQL was used to cache slow-changing data; it was linked to the memory grid for message passing.
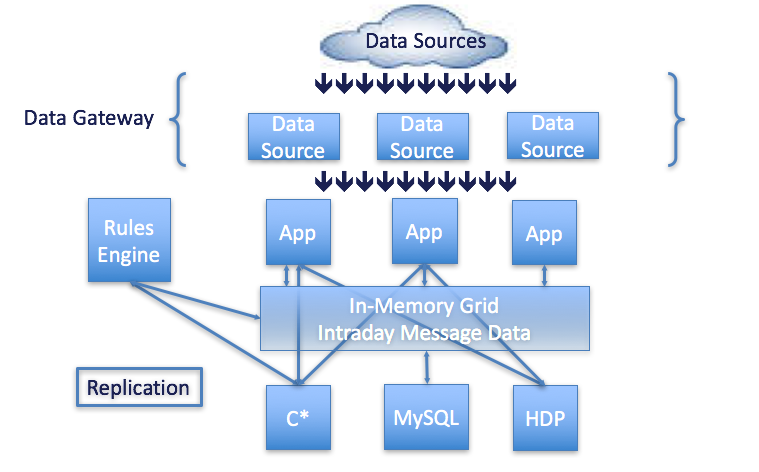
Additionally, a rules engine that needed high-speed access to daily event data sat at the front end of the data pipeline. The rules engine needed fast access to the Cassandra cluster. As the platform and rules engine received updates, intraday data became available that traders used to make recommendations or buy/sell orders.
As with all financial organizations, this operation has a highly proprietary workflow for processing large trades. The workflow required state to monitor the bank’s position in various securities, as well as a workflow to monitor and provide intraday data on market pricing, best pricing (see the NBBO example application), timing, and market liquidity. State about investors, their trading preferences and market positions was also maintained.
The use case is characterized by a complex system with a big, fast incoming stream of data. The system included multiple replications of that data and a rules engine that needed various views of intraday data. Complexity was the biggest challenge the bank had to manage – different databases holding replicas of the same data were pain points; the need to query fast-moving data was a pain point; a further pain point was the regulatory requirement that the bank had to meet to prove the different replica databases were all the same, with audited consistency across different data sources. The bank was dealing with cost complexity, operational complexity and regulatory complexity.
After
The bank turned to Volt Active Data to simplify its architecture, improve performance – it was experiencing severe bottlenecks in its Cassandra cluster – and maintain state while executing fast queries and transactions. Volt Active Data was inserted early in the event flow of the trading data, coming into a message bus or a queue – an internal version of Kafka.
Volt Active Data sees the majority of messages arriving over the message bus, functioning as an intraday cache of all event data from incoming trades, orders and fills. Financial analysts can query Volt Active Data directly. Volt Active Data also maintains some analytics functions, including the volume-weighted average price and time-weighted average price of various securities being traded. Data events are republished, or side effects of events are connected with Volt Active Data’s fast export functionality back to the message bus. These events include calculations on fresh orders that trigger and satisfy business logic in the rules engine. When the rules engine’s requirements are met, a message is published to the message bus, causing other events to occur downstream.
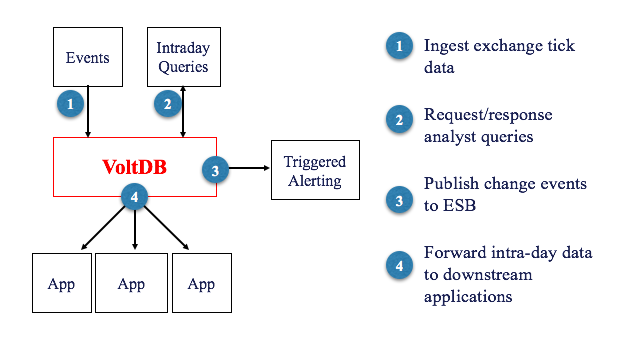
Volt Active Data serves as an intraday cache of trading and state data, and also as the database of record. If applications fail during the day, data can be read back from Volt Active Data: Volt Active Data is a recovery source for intraday data and a persistent cache for recovery.
Volt Active Data solves a combination of three problems for the bank. It’s a queryable database engine analysts can query to understand the bank’s position (state); it maintains streaming calculations used to import business logic about trading on different data management components; and it’s a state-flow intraday message cache for trade data. With Volt Active Data, the bank can read the intraday state to satisfy the rules engine, replicate intraday data to historical databases, and drive analytic results before pushing processed data at high speed through Volt Active Data’s export.
Net
The above use case may seem to call for a streaming solution, but it’s really a database problem. Why?
Three things are solved using a database that couldn’t all be accomplished with a streaming solution:
- Ingestion of high-velocity streams of events or requests
- Processing of event data that requires state: some amount of history, or some amount of analytic output
- Per-event, automated actions on events that are then passed (exported) downstream.
In addition, Volt Active Data exports data to Hadoop and other long-term stores at the same rate at which it is ingested into the system.
Conclusion
Many developers and enterprise architects might look at this use case and see a streaming application, but there are aspects of a streaming-type application that aren’t solved well by a streaming tool. They’re really OLTP problems. There’s a performance requirement for a high-velocity component that’s often seen as a streaming problem, but there’s also a need to process events that require some history in order to make a decision – one where you want to take automated actions as events are arriving. You also want to capture the results of the high-speed event feed for export.
You may think a database can’t solve all these challenges, but we’ve found many enterprises which start with another technology, run into issues, and then find Volt Active Data – a state-flow database – that provides fast ingest, real-time processing of per-event data, automated actions, and fast export. Combining these four things can provide a fast, elegant and simple solution that meets all (or most) of your data management challenges.
Look for the next segment of this blog series – Before & After – using Volt Active Data in the IoT.




